The Indieweb privacy challenge (Webmentions, silo backfeeds, and the GDPR)

Originally intended to showcase a privacy-centred implementation of emerging social web technologies - with the aim to present a solution not initially motivated by legal requirements, but as an example of privacy-aware interaction design - my "social backfeed" design process unveiled intricate challenges for Indieweb sites, both for privacy in general and legal compliance in particular.
With privacy on the agenda everywhere (aka. "last-minute GDPR panic"), I regularly receive inquiries about my implementation of some Indieweb features on this website. I have always been openly enthusiastic about the long overdue regulation of the use of personal data in a technologised world, even though I too see the sometimes almost unsolvable challenges that some of these rules pose in practice. My primary motivation for promoting privacy-aware design, however, have never been legal requirements, but the belief in shaping technology based on people-centredness, respect and transparency.
Hence, it is with a mix of curiousness and concern that I try to wrap my head around some of the challenges of creating social interactions in a decentralised manner, while respecting the privacy of people and keeping them in control over their own data ...at the same time meeting the strict requirements of (EU) privacy laws.
The Indieweb: advanced social features for the web
One of the things I have been fascinated by for years is the Indieweb - a movement that aims to develop and establish techniques for social interactions on the open web; much like the "closed silos" of social media, but in a decentralised manner where users retain sovereignty over their content.
The techniques and tools developed by the Indieweb community for taking ownership of content and syndicating it to online silos are as straightforward as they are ingenious:
-
Authors post all their content on their own website, then use POSSE syndication mechanisms to share it elsewhere (e.g. to reach audiences on Twitter, Flickr, Facebook).
-
When other Indieweb users interact with this content by replying, liking, bookmarking or sharing on their own sites, their websites send a notification using the Webmentions protocol, allowing the original author to read and possibly (often automatically) publish these responses.
-
In an extension of that logic, it is also widespread practice to pull in the backfeed of social interactions from other platforms that do not send Webmentions themselves (for example Facebook comments, Twitter likes, reposts, RSVPs etc.), using either specifically tailored pieces of code or free "backfeed proxy" services like Brid.gy.
It is a brilliant loop: Authors always keep the master copy of their content, enable others to consume the content in their preferred channel, and aggregate feedback and follow-ups in the context of the canonical copy.
The issue: taking ownership of others' data
I've been using some of these mechanisms for a long time and it's been working well and aggregating feedback nicely. It is actually a fascinating feature. Yet, a few observations have always unsettled me regarding my implementation - in particular of the social silo backfeed.
Three observed issues ultimately triggered a redesign last year:
1. Misrepresentation of meaning
First of all, I regularly notice more Twitter users "liking" my syndication tweet than the number of clicks the (unfortunately compulsory) t.co click counter reports. This indicates that "liking a Tweet" does not necessarily reflect an endorsement or feedback for my 2000-word article that tweet was linked to, but may as well just be a user's way of bookmarking interesting tweets, a way to signal to me that my efforts around a certain topic is appreciated, a general "poke"-like social interaction - in short: a Twitter "like" does not equal a reflected "favouriting" of my full blog post.

Displaying a Twitter "like" as a "like" under my blog content does therefore not always reflect the intention of the person who clicked that button. Changing such meaning without affirmative action by the individual concerned is, in my opinion, at least questionable.
2. Opaque processing of personal interactions
Secondly, while a Twitter user technically "publishes" a message for all world to see as they like or retweet a tweet, the consequence that simply pushing a button within Twitter will result in their profile picture, name and "endorsement" being displayed on a third-party website may not be understood.
Presenting such users' actions with their full name and mugshot on a website (inevitably getting their names indexed for that website by search engines) makes these interactions more public than users may intend. Such "surprise" processing of personal data is always a red flag when designing for pricacy (and, for example under the GDPR, definitely risky terrain in legal terms).
This had been previously identified on the Indieweb wiki, with a handful of documented approaches to tackle the issue; all based on publishing a note about the backfeed practice more or less prominently on the silo profile or feed. For me personally, none of the discussed solutions fulfilled my requirement, wanting to ensure that I only process data of users fully aware of what I am doing.
3. Taking away control from others
Thirdly, while the idea behind pulling in the social backfeed is about "owning the conversation" around my content, an Indieweb site is at the same time also taking ownership of other peoples' content, expressions and conversations - this comes with responsibilities. The Webmention protocol in principle supports edit and delete commands, i.e. if another Indieweb user edits a former reply to my post, they can send an automated notice, which then should update or remove the response on the receiving end.
When pulling in social silo feedback, this is not necessarily provided for - at least with most current implementations, "unliking" a tweet later will not reliably remove it from a site with a backfeed. Definitely not something that privacy practitioners nor privacy legislators like to see.
Time for a redesign?
Encouraged by deep discussions on general questions of tracking, privacy and webmentions at a Homebrew Website Club Berlin meeting in early 2017, I got the motivation to rethink my backfeed design based on these observations - to better reflect the nature of these interactions, but also to demo and test-drive "privacy-aware web design" and the application of the "minimum actionable dataset" design principle.
I was soon to find out that these objectives may easily clash with the underlying "enable social interaction" objective of the Indieweb.
Coming to terms with laws, terms & conditions
The redesign effort was further inspired by exposure to some developments in terms of privacy terms and regulations, which motivated me to do a proper concept review of my social media backfeed:
GDPR
N.B. This text does in no way constitute legal advice. I am not a lawyer, and not qualified to provide legal advice. All content, provided solely for informational purposes, has been researched with greatest care, but to create legally compliant solutions, you should always consult a lawyer or solicitor.The EU's GDPR regulation, enforced as of 25 May 2018, sets tight rules on processing personal data, with possible implications when displaying syndicated data from other sources.
Most of the data required in order to display a backfeed is "personal data" in the GDPR sense: the name of the person, the URL to their Twitter profile, the avatar image, all fall under the rules of the regulation - triggering high requirements as to the rights of the people concerned (and, contrary to some voices, there is no reason to believe that it having been published elsewhere would render it any less "personal data" in a legal sense; the only difference could be that it being publicly available may shift the weights when trying to justify the applicability of "legitimate interest" as the legal grounds for processing, rather than consent/contract).
Given that, in the case of syndicated backfeeds, no silo user actually interacts with the Indieweb site directly makes it for example almost impossible to inform them about the processing of their data, as required by Art. 12-14 GDPR.
Silo rules
Furthermore, the latest version of Twitter's Developer Policy document, effective as of 18 June 2017, for instance requires API users to only display Tweets still available on Twitter (ref. C.4). This means that displaying Twitter backfeed messages would formally require to at least verify all silo replies every time before displaying them. This is one of many rules in Twitter's terms that obviously relate to the GDPR: Twitter users have the right to delete their data, and Twitter has to ensure that every API user who had accessed that data also deletes it, in order to fulfil their own legal obligations.
Details on the design process (click to read)
Reflecting on design drivers
Before redesigning a feature, it is good practice to first reflect on the overall motivation for its existence. Building on the brainstorming at the Homebrew Website Club and the respective Indieweb.org wiki entry, I came up with five reasons why Indieweb users may publish their backfeed - here listed in the order of priority I would put these in for myself:
- convenience: for the author, as an easy way to see who has replied to their writings, but also for others who can leave a comment on a website while staying within their preferred environment
- archiving: even with silos long gone, the discussion surrounding my content stays in place
- aggregation: commentary/feedback otherwise scattered around the web is aggregated in one
- facilitation: enabling others to see who of their peers have also reacted or what they have commented, hence enabling a conversation beyond silo borders (in particular within tight social circles like for example the current Indieweb community)
- social proof: being able to show that others have read and reacted to content may increase its value or reputation; an aspect whose importance varies significantly from person to person (myself and a lot of my peers mainly publish for their own motives, not for building reputation, but it obviously is a very valid motive for a backfeed).
The initial design solution: anonymize
I then moved on to implement what I - at the time - believed to be a good solution to solve the ethical issues I saw in the original "full silo backfeed" feature.
Weighing the affordances
Looking at the list of motives above, it becomes apparent that, apart from the aspect of "facilitation", none of these would require to publish the identity of those who have reacted to my content (or as stated above, even just to the syndicated notification about it). By keeping the identity of individuals on my backfeed private - whilst still showing a "response count" and linking back to the canonical copy of each feedback - I still meet the following criteria:
- I can conveniently see all replies in one place, and silo users can send these comments from within their use context as preferred
- all conversations around a piece are archived on my site for my own use
- all feedback is aggregated in one place
- just displaying the amount of feedback and linking it back to where it can be assessed still adds "social proof", as the names and faces of strangers do not add any more value to this as does a backlink to where these could be accessed and verified as genuine reactions.
The only aspect negatively impacted by anonymizing the backfeed is the facilitation of interactions between those interacting with my content; this is an obvious shortcoming (especially knowing that this facilitation is one of the core objectives of the Indieweb), but since we are acting in a public context it might be the price to pay for protecting other individuals' privacy. This is where aforementioned clash between privacy objectives and Indieweb objectives becomes most tangible.
Design variables: implicit/explicit, intentional/unintentional
Putting aside the legal aspects (that I had not grasped to the extent I do today), I was looking at two relevant user experience variables as I evaluated my backfeed design concept:
- Intentionality of providing feedback to be presented on the original content's website is only given with "genuine" webmentions, i.e. if a user reacts to a post using their own website or a service specifically designed to send out reactions as webmentions (such as Indieweb sites); any automated silo backfeed from third-party networks is not in most user's initial intention; even though, within the Indieweb community, users might expect such functionality.
- An explicit desire to publicly comment on a piece of web content could primarily be assumed when a user writes a commentary along with the reaction (such as a retweet with a comment, or a reply message on Twitter), in which case presenting it on the canonical website copy could potentially be thought of as a kind of "quote" as a common social convention; in other silo actions, such as simply pressing a retweet or favourite button, the publication of that expression is of more implicit nature (i.e. not all users may always be aware of becoming a publisher, in particular with favouriting, as these are commonly not very exposed, e.g. may not be indexed by search engines).
The initial solution: anonymizing "not intentionally submitted" feedback
Following this train of thought, I changed the implementation of social silo backfeeds on my site: I decided to "anonymize" all reactions that I consider to be potentially unintentional (regarding their prominent public display, notwithstanding the fact that it is of course, unless deleted, public information by nature) and of rather implicit nature (as in: how conscious a user may be of their action).
In order to maintain the great value of convenience, archiving, aggregation, facilitation and social proof, I decided not to hide the interactions completely, but rather ensure that the individuals' names and portraits do no longer show up on the site publicly. They are still linked to the original interactions (simple hyperlinks to the silo copy of my content, indicating that "I have been made aware of feedback there") and can be followed up within the silo UI as long as they have not been deleted.

Furthermore, to the logged-in admin user (i.e. myself), all names and avatars would still be shown as before - ensuring the ease of conversation overview that I was primarily looking for when I decided to "take ownership of my content and its surrounding conversations". This in a way resembles implementations of many social network silos, where visibility of "reactions" can be limited to a smaller audience than a post.
Implementing the change was rather straightforward. Since I had always cached silo users' avatars on my own server, all I had to do was to instead generate and store a pixelated copy of each avatar in the process (as a design element, avoiding to use "egg heads" or other generic placeholders) and change the Wordpress template to serve anonymized markup to anybody but myself.
Evaluating the design - or: "then came the GDPR"
The "anonymized silo backfeed" was a feature I was pretty happy with. As discussed above, apart from one small aspect, the feature would still facilitate most of the motives for having it displayed, yet it solved all of the initial issues I had identified:
Silo users (e.g. on Twitter) no longer would be surprised about finding their name and image, along with a potentially misinterpreted "like" action, on my website - and by linking back to the original silo interactions, the silo users would stay in full control over their own content (for example to delete it) while it would still be easily accessible from my site. At the same time, I believe that this solution solves potential conflicts with silo T&Cs (with the "delete" requirement the only one that I am actually aware of; given the complex structure of Twitter's terms and conditions spread over various documents, I've never been able to determine for example the copyright questions around displaying avatar images from Twitter outside of the Twitter-provided embed features).
The solution still processes personal data
Now, I have spent a good share of my awake time over the last half year on complementing my privacy-led design perspective with deep insight into the legal field, familiarizing myself thoroughly with the GDPR. This was not an intentional move at first (really, what designer-researcher wants to become a privacy law expert?), but when advocating privacy-centred design practice, fluency with the complex legislation is a must. And complex it is. But, I admit, also extremely fascinating.
Reflecting over the "silo backfeed" once again, I today see a range of further issues, even after redesigning the feature last year. Most importantly: I was still storing personal data on my server that I had obtained without the "data subject" (GDPR-speak for the person whose data it is) being aware of it. Even though it is not displayed to anybody but myself, the name and URL of the silo user still got stored in the database - a processing activity of personal data, falling under the GDPR's rules.
A database full of personal data
In order to maximise compliance with the GDPR, I recently did an audit of my database (in this case: the Wordpress database) to identify any personal data being processed. This is the first step in order to document the legal grounds for processing: processing personal data is by default always prohibited unless the "data controller" (the website owner) can prove it to fulfil one of the six requirements of Art. 6(1) GDPR.

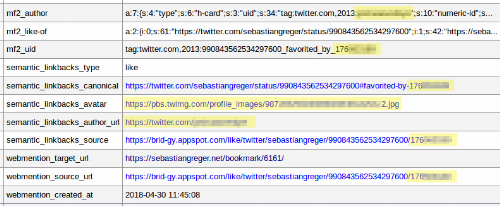
All fields marked yellow in the screenshots above represent "personal data" as per the GDPR definition (here: information that allows to identify an individual), and can only be processed/stored based on one of the six legal grounds for processing defined in Art. 6. As said before, the fact that it was retrieved from a public service does not change that. In order to adhere to the law, the website owner has to comply with the requirements imposed by the GDPR.
Doubt over current Indieweb sites being "purely personal"
And, while some may disagree, I personally believe that the GDPR is of concern to most current Indieweb users based in the EU. The sometimes cited conditions for exemption of Art. 2(2) lit. c GDPR are formulated very strictly: "by a natural person in the course of a purely personal or household activity". This is further specified by Recital 18(1) GDPR (emphasis mine):
This Regulation does not apply to the processing of personal data by a natural person in the course of a purely personal or household activity and thus with no connection to a professional or commercial activity.
Based on the German legal literature I have assessed, this would make the GDPR applicable to a personal website as soon as its content has any connection to professional or commercial activity, hence not only applying to freelancers, who undoubtedly are affected, but e.g. to any web professional who discusses web technology on their personal site (the entire "Indieweb generation 1"?).
Legal basis for processing a silo backfeed?
This is where things become complicated. Nothing unusual, given that it is May 2018: this kind of tricky questions - where existing practices suddenly turn out to be in conflict with one or several of the requirements - are exactly what keeps web professionals and privacy lawyers in the EU so busy these days.
Legal grounds for processing?
Despite "consent" getting the biggest media attention, the most commonly applied basis for processing in practice is "legitimate interest": the data controller carries out (and documents) an auditable assessment that their interest weighs stronger than the privacy interest of the data subject.
In the case of displaying aggregated reactions to web content, I can see that a "legitimate interest" argumentation could possibly be defended in principle. After all, the personal data in question is already public (always a strong factor towards the interest of the data controller) and the data is - depending on the site content - of rather low impact. Having a feature in place that validates displayed reactions for possible deletions on their originating site would be another strong argument on the "pro" side. On the "con" side, I would at least list my three initial headaches that triggered this entire process.
Transparency?
Yet, being able to demonstrate that the site owner's interest is greater than the need to protect the data subject's privacy is not enough. The GDPR still requires that the data subject must be informed about the processing. With data being aggregated from the API of a social media silo, that is almost impossible.
To my positive surprise (this is an understatement: to my greatest joy), the exact question of Indieweb silo backfeeds was brought up on the recent episode 55 of the "Rechtsbelehrung" podcast, one of the most prominent German podcasts on legal questions of digital technology, with an equally prominent lawyer in the GDPR field, Dr. Thomas Schwenke (author of a popular GDPR guide for entrepreneurs, and in my opinion one of the go-to sources for solid online legal information in Germany).
Keeping in mind that a podcast is never binding legal advice (and that Dr. Schwenke's assessment was not based on thorough knowledge of the Indieweb mechanisms), here is my paraphrased understanding of the key points from that brief discussion (for German-speakers: tune in at 1h 11min) after Host Marcus Richter posed the question:
-
Individuals have to be informed when data about them is pulled in from third sources
-
Pulling "likes" and profile images from Twitter in Indieweb manner (in my opinion precisely described by the show host) requires a statement in the privacy notice and the affected persons have to be informed, whereas pulling in aggregated data only ("this post was liked 50 times on Twitter") is not personal data
-
An exception applies if it can be assumed that the affected persons are already aware of it (informed about this by, in this case, Twitter); here, the question would be whether the users could truly be considered to be informed sufficiently and - at this point the podcast briefly diverts into an interesting comparison to the Cambridge Analytica case - whether the third party's use of the platform data is in compliance with the terms for that API
-
If relying on Twitter users to have understood, when signing up, that their data will be made available for third-party use, it may be not necessary to have separate acceptance for reusing that data externally; if building one's own argumentation for lawfulness on this, it needs to be made explicit in the site's privacy statement
-
In case of a legal dispute, the website owner has to be able to demonstrate that the Twitter users were informed
As with all things GDPR, it boils down to risk assessment. While Dr. Schwenke presents a possible way to declare the processing lawful by building on the fact that Twitter users have accepted third-party use of their data, he also (implicitly, in the very last words before moving on to the next topic) refers to one of the big risk factors of the new legislation: the data controller (here: the Indieweb site owner) would be responsible to present proof that the data subject (here: Twitter user) was indeed aware of this particular reuse. No matter how well the backfeed feature is described in the privacy notice of the site (an absolute requirement as well), the challenge remains that the site owner is responsible for being able to prove (when challenged) that the data subject could indeed be aware of the processing.
It's complicated!
At this point I need to specify my outbreak of joy described above: I was mostly happy about (a) the Indieweb idea surfacing in a podcast with over 10.000 listeners and (b) the fact that a reliable expert would give some comments on the topic. Less reason to party is the fact that his brief initial assessment reassured me that my own hunch had been correct: processing the personal data that is "people's reactions on publicly accessible social media" is indeed a legal swamp (I first wrote "legal minefield", but needless alarmism is not how I like to get my points across, so keeping it neutral).
From what I understood based on many discussion over the last months, the Indieweb is not the only social technology stack facing this kind of challenges; Mastodon, for example, with its federated model of content distribution, also faces conflicts between technological possibilities and potentially undesirable legal implications for the users (off-topic here, but it was related to Mastodon servers potentially hosting federated third-party content that is considered illegal under some legislations).
A permission layer for Webmentions?
Given all considerations above, I believe that there is one core issue to be solved before reaching a state where using Webmentions - and silo backfeeds in particular - could be considered fully privacy-aware (ethically) and risk-free (legally):
Every site owner processing Webmentions would need a means to document that the individual from whom the Webmention originates is aware of the processing it will undergo and has no objections to it (the latter does not have to be "consent", which comes with a range of practical consequences under GDPR, but could also be the provision of a means to object under a "legitimate interest" justification).
This comes first and foremost from the ethical consideration that a person's data should never be processed without them being in the know and ok with it. In practice, however, the maybe even more burning issue is that the (EU-based) website owner would have to be able to prove that in a case of dispute.
I could not find anything documented, but have been made aware that some initial ideas have been discussed at IndieWebCamps. One such idea would be to implement a mechanism that informs a Webmention sender on the first time such message is being received from that source, and only process it under the condition that it is either not refused (an opt-out approach, probably to be considered when relying on "legitimate interest") or confirmed (opt-in, as common under the "consent" category of GDPR legal grounds). On a related session at the IndieWebCamp Nürnberg 2017, the particular question of copyright for profile images (in a scenario of Webmentions between Indieweb sites) had already been discussed, leading to some ideas on including a license in the markup.
In the light of recent developments on the legal front, approaches to solve the issue appear to be one of the maybe most urgent needs for a people-first federated social web. For now, with mainly Indieweb enthusiasts using Webmentions, the generic use case (not through social silo proxies) could probably still be considered to take place within a community that is aware of the implications, but once Webmentions mature into a feature in bigger platforms or software like Wordpress, it can no longer be assumed that every sender of a Webmention is aware of it. As a matter of fact, it is already today possible to send a mention on somebody else's behalf (the protocol only verifies that the submitted URL indeed links back to a post, but not who made the request to process it as a Webmention).
Compliant backfeeds in the future?
Using a social media silo backfeed in the way it is commonly implemented today may not be entirely impossible from the legal perspective, as presented in the "Rechtsbelehrung" podcast (building the argumentation on Twitter users having consented to the service's terms on third-party data use during sign-up, informing comprehensively about it in the privacy statement, and ensuring that the implementation is 100% compliant with all applicable API, developer and service terms). Yet, as also becomes clear from the podcast, this argumentation comes with heaps of potential points of failure that could later lead to it being declared unlawful in a legal dispute (did the user really agree to this specific use in the Twitter T&Cs? were the Twitter terms really understandable enough for the user? does the backfeed solution truly adhere to every single API rule in place, e.g. almost instant deletion of mentions based on deleted Tweets?).
From an ethical design perspective, however, I still have a stomach ache thinking of publishing the name and image of unknowing Twitter users on an unrelated website, presenting a "like" potentially intended as a bookmark of a short tweet as a "like" for a long essay on some blog site they have never visited. Here, too, some kind of transparency/consent mechanism would be required; and while I am sorry to not have a ready solution to offer, the idea of simply warning about a backfeed in a sticky post on top of a timeline is not really something I consider sufficient. Likely, the solution for the silo backfeeds would have to come after a solution for Webmentions in general has been developed.
Beyond mentions and backfeeds
Since the data to display Webmentions and/or backfeed reactions is personal data under the GDPR, this comes with further responsibilities related to the rights of individuals. Even when the processing of these interactions is based on a (hopefully stable) legal basis, implementation challenges remain as to the rights of individuals to demand information, rectification, deletion of their data; potentially transferability as well. On a small scale, this can be carried out manually, but for scalable solutions, any website dealing with personal data would have to be able to do that in an automated manner.
Some communities are already actively working on solutions to provide CMS plugins with a centralized GDPR dashboard to deal with such requests; for example GDPR WP as the most prominent initiative for Wordpress (apparently even becoming a core feature in the very near future).
As we build techniques to display federated social interactions on websites, dealing with individuals' exercise of their privacy rights will be another important foundation for a future-proof and privacy-respecting framework (and, not to forget, legal compliance).
(Personal) Conclusions
As you can tell from the length of this post, I have been putting a lot of thought into the privacy implications of Webmentions over the past year. I still believe in the idea of decentralised social networks, and I do want to see Webmentions and similar inventions succeed. When approaching current implementations with a strictly (maybe even radically, if it serves the purpose to spark a debate) privacy-centred view, however, it seems that there is a mind-boggling range of issues to be solved if the Indieweb - or other decentralisation movements - want to be not only in control of their own content and interactions, but also deal respectfully with the content and interactions of others.
These are major challenges for the big social networks, and the GDPR was not least authored with their often questionable practices in mind, so it cannot really be expected that it would be easy for the underdogs, either. If anything, I have come to believe that the decentralised nature of solutions like the Indieweb makes the management of privacy interests even more intricate. By building a solution based on making everybody a website owner (and hence, many of them a "data controller" under the GDPR) as is the core of the Indieweb idea, we cannot rely on the same comfort of making all participants sign a common contract and then operate freely within a walled garden as the big silos do.
I wrote this article to document my approach - for open discussion in true Indieweb manner - and do not intend to judge others. Most importantly, I hope this text can trigger a widespread discussion about the privacy implications of building a social network that is entirely open. I admittedly draw my conclusions from a rather strict ethical baseline, but do respect that others' compass may be calibrated differently; new solutions can only emerge from constructive exchange over different positions. Maybe this article, and my recent thoughts on "The GDPR as a call to practice ethical design" can be worthwhile contributions to such process?
Given the considerations above, and the GDPR enforcement deadline three weeks away, I decided to at least temporarily remove the Twitter backfeed from my site, delete the personal data accrued in the database, and disable my Brid.gy account (shedding a little tear, as it truly is an ingenious concept and service). While I still believe that my pixelated and de-personalised presentation of the backfeed solved at least most of the ethical issues, I personally don't want to jump through the hoops of drafting a privacy statement with a shaky argumentation about the lawfulness of storing all that data. At the same time, this releases me from the need to think about how to deal with individuals' requests as they may execute their rights under the GDPR; it makes this site less social, though - a strong motivation to keep thinking about solutions!
I will keep my Webmentions endpoint open (for now relying on "legitimate interest" and the fact that Webmentions are still a niche feature), but all incoming "generic" Webmentions will be moderated, only accepting mentions from sites that make use of Webmentions themselves; that way, I can safely argue that the sending user was aware of the implications. All other incoming Webmentions will be deleted within a few days - a "privacy by default" feature in the GDPR sense.
Maybe this is also the first step in moving away from the overall reliance on Twitter as a notification channel? Quite frankly, most of my Indieweb contacts still appear to subscribe my posts over Twitter, not the open web - something I would like to change. The recent activity surrounding an "Indie Reader" is a welcome sign in that direction.
Talking to some social activists at last year's Datensummit 17 once again highlighted how protecting other users' privacy when sharing content of conversations not intended to be publicized widely (even if they may be undertaken in a public space; this is an important consideration!) is of great importance. And as a publisher, it is everybody's responsibility to consider these aspects. Just the fact that I can aggregate a "facepile" showcasing everybody who clicked "like" on a tweet of mine does not mean that my motivations for doing so are more important than their right to stay in control over that interaction.
Please feel free to comment - below or via Webmentions - if this triggered any thoughts. I am looking forward to collaborate on working out how privacy can be a core aspect of the Indieweb.
Footnotes
- That said, I strongly believe it is not the legislation that is flawed (though it undoubtedly has some major shortcomings), but this process is so painful because we have gotten used to so many ways of "doing things" that are in conflict with protecting peoples right to privacy; ref. also my post: Eight valuable insights from a panel on opportunities of the GDPR.↩
- I am using a DIY connection to the relevant posting APIs from within my own Wordpress plugin, and the Brid.gy service for aggregating the backfeed, fed back into Wordpress using the community-developed Webmention and Semantic Linkbacks plugins↩
- See also the "Pro/Con" arguments on the Indieweb Wiki page on "backfeed", where certain concerns are articulated; also the wiki page on privacy documents at least one critical voice that the Indieweb may benefit from more debate on privacy questions.↩
- At the time of this writing, the Indieweb wiki page on GDPR quoted Art. 9(2), stating that it would exempt published data from falling under the GDPR. Based on my reading, this is not correct, as Art. 9(2) only exempts published data from the special requirements of Art. 9(1) for "special categories of data", not from being considered personal data in general; e.g. the recently published Guidelines on Transparency by the Article 29 Working group clearly indicate under nbr (26) that also data from public sources must be treated as personal data to which the rules of the GDPR apply.↩
- I explicitly refer to the awareness, not consent, here - the myth that GDPR is all about 'consent for everything' is #gdprubbish and something I actively try to educate about being false.↩
- In this case, Art. 14 GDPR would apply, as the data is not obtained directly from the data subject.↩
- I have some ideas for getting a backfeed-like feature back eventually, but for now unfortunately don't have the time to pursue that any further.↩