“Own your data”, part IV: Avoiding search engines that track their users

What does the 2014 web user do when they don't know the exact address of content on the web? They "google it". Many "google" everything, using the Google search box even to browse to a domain name they want to visit (it is stunning to see how common this is when observing users "in the field"). And a wide range of browsers default to "googling" on the user's behalf if an entered URL is not valid.

What is happening as we "google" something is essentially that we are telling a huge corporation what is on our mind right now and we trust that this corporation then knows to lead us exactly to what we are looking for. Since we are doing it repeatedly, dozens or even hundreds of times a day, we not just accept but appreciate that this corporation knows every one of us so well they can make tailored suggestions to everybody.
And as the very same corporation also runs a wide range of hugely popular "free" (as in "no monetary cost") services from maps to the world's most popular video hosting platform and most significantly today's almost default e-mail service, a huge share of those using the search engine are also registered users and therefore not just profiled but individually identifiable.
Convenience, at a (high) price
The implications of Google being able to profile a majority of internet users, while easy to put down with an unreflected "I don't have anything to hide", are severe. By centralizing a history of anything that crosses all internet users' minds, along with precise timestamps and often a geographical location, the company creates a giant database of interests, behavioural patterns, locations and more - in most of cases directly connected to a personally identifiable individual.
It needs to be remembered, that the sheer existence of this data is a privacy risk, even if its current handling may be safe; despite its hunger for profile data, Google has a privacy policy and at the time no doubt strictly limits itself in the use of the collected data to the broad permissions we as their customers grant them (you did read this document carefully when signing up for your Google account, didn't you?). A data leak at AOL eight years ago gave a taste of what may happen when personal usage data profiles accidentally become available to third parties:
No matter whom each of us may not want to get hold of such private information - Google itself, governmental agencies or potential data thieves - the best protection would be if such archive would not be created in the first place. Why is it then, that a billion people keep "googling" away day in and day out? Just because Google, with its access to unlimited funds and huge server farms, is presumably the only player able to help find content on the web?
Naturally, Google is not interested in offering a possibility to use the search engine without tracking. It conflicts with its very business model - monetizing on its users' information. After all, the only reason Google is able to build such gigantic search infrastructure is because we each pay for it with giving up our privacy, one search at a time.
Using Google is optional!
There are, however, alternatives. Back in the 1990s, meta search engines were the answer to advanced information retrieval needs, when all that was available were manually updated indexes like Yahoo and early web spiders like Altavista. Meta search engines queried a wide range of search engines and ranked the results based on an algorithm.
A lot has happened since then. With fulltext indexing and semantic software able to "understand" the content of a web page, search has become much more complex. And proprietary technology makes some search engines better than others. But the concept of the meta search engine is seeing a renaissance: maybe not quite able to compete with the smartest of full-text indexing algorithms, their power resides in the combination of several engine's results and in the obfuscation of the user's identity.
Free from surveillance - and the filter bubble
For the past year, I have almost exclusively been using alternative search engines. What started out as a self-experiment soon became such routine I almost forgot to write this blog post for my "Own your data" series.
Granted, Google's services are still hard to avoid completely, but already reducing their use to when absolutely necessary is a major step towards more privacy. I still occasionally fall back to Google's map search when OpenStreetMap does not provide the geographical data I need and Google's image search is so far unmatched by its privacy alternatives. In addition, I sometimes just have to verify certain searches on Google for work purposes or I may want to ensure to have searched exhaustively on a topic (e.g. for research, in which case also a Google user would refer to other engines for completeness).
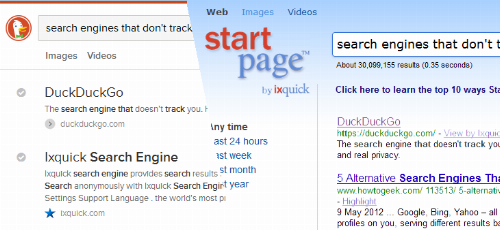
But for most of the time, I have been more than satisfied with the results and usability of my two preferred alternatives, DuckDuckGo and ixquick/startpage.com. While there are certain differences between them, their common baseline is a very people-centred understanding of privacy. Gabriel Weinberg, the founder of DuckDuckGo writes:
From funny videos to health and finance questions, searches are a reflection of your personal life. That's why we don't collect or share personal information.
And ixquick assures its users:
When you use Ixquick, we do not record your IP address, we do not record which browser you are using (Internet Explorer, Safari, Firefox, Chrome etc.), we do not record your computer platform (Windows, Mac, Linux, etc.), and we do not record your search words or phrases.
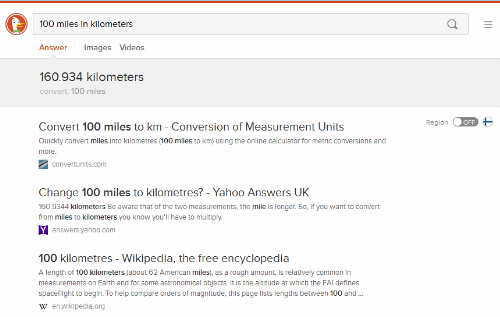
In my continued use over almost a year, I found that both engines deliver almost always what I am looking for. By integrating a meta search through Google, ixquick's startpage.com service delivers result listings often very similar to Google itself - minus the profile bubble. At the same time, searches on ixquick.com and DuckDuckGo have the major benefit to rely on more than one algorithm, therefore often lifting up results that Google would hold back from its users as considered irrelevant. DuckDuckGo is integrated with Wolfram Alpha, offering quick math results or currency conversions straight from the search box.
Another step towards a private browsing strategy
Adhering to a philosophy where only data absolutely needed to provide the desired service is being collected (cf. my recent post on MAD, the "Minimal Actionable Dataset"), DuckDuckGo and ixquick provide powerful internet search that makes using Google obsolete for the majority of daily search tasks.
Using an underdog alternative undeniably comes with minor limitations; sometimes a dissatisfying search result just forces me to fire up a Google window to look for alternative results. Minor inconveniences are the price to pay for privacy at this point - looking at the limited resources compared to the giant in the market certain disadvantages are obvious.
On the other hand, I found the switch a very enlightening experience as the initial discomfort with the slightly different kind of results revealed just how much Google and its pre-filtered results have conditioned our brains what to expect from a search engine; once getting used to the new service, none of the initially alienating details has proven an issue. Quite the opposite, I feel liberated to be able to decide by myself what I consider relevant and what not.
It goes without saying that switching to an anonymous search engine makes most sense as part of a larger "private browsing" strategy: if you use Google Chrome and synchronize your browsing history to their cloud or if you haven't blocked Google Analytics using a plugin like Ghostery, Google is still able to amass comprehensive browsing history on you.